
Yeah the documentation (if it even exists) of most projects is usually clearly written by people intimately familiar with the project and then never reviewed to make sure it makes sense for people unfamiliar with it. But writing good detailed documentation is also really hard, especially for a specialist because many nontrivial things are trivial to them and they believe what they’re writing is thorough and well explained even though it actually isn’t.
Bold of you to assume I know how to read!
This is why Technical Writer is a full time job.
It’s also why the humanities are important. Stemlords who brag about not doing literature classes write terrible documentation.
My CS major required me to take two upper division English classes and I think they helped me more in my career than my upper division CS classes. People forget that documentation is for ourselves too
I’m really thankful that I had a great English teacher in high school, and that my degree required a technical writing class. Being able to write a coherent email got me further in my career than the technical stuff I learned in college.
I completely agree. Most peer feedbacks that I get mention my documentation. It has helped me so much
I think this is why the “my code documents itself” attitude appeals, even though it’s almost never enough. Most developers just can’t write, nor do they want to.
The problem with “It’s self-documenting” is that there are inevitably questions about what it says, and there’s no additional resources to pull from.
“my code documents itself” and “no, our CI system doesn’t upload the source jars to Artifactory, why?”
Maybe, just maybe, people have different strengths and weaknesses and cooperating around our differences is what makes us succeed.
If you know your weakness is writing documentation, please hire a technical writer.
That’s exactly what I’m saying, sorry if it came across somehow askew.
My point was there is no point in competing over whose job is “better”, we should be working together.
There is a case to be made that people should be a bit more well rounded in general, and not just find a specific niche.
So non-technical people should still have a decent familiarity with computers and maybe be able to do some very basic coding. And technical people should spend some time working on their written and verbal communication.
Because in both cases, it makes people more effective in their roles.
Most open source projects rely on volunteers, and few technical writers volunteer.
Totally agree. And I’d argue that we don’t even need technical writers. Even if all people do is correct grammar and spelling mistakes it would be helpful, let alone actually writing docs. It’s one of the easiest ways non-technical folks can get involved with open source projects.
Every time I get stuck on something confusing I’m a README and figure it out I try to submit a patch that makes it more explicit.
If the documentation is sufficient for the intended audience, it’s good enough.
Humanities are very important. Robots are not yet capable of flipping burgers!
Robots can definitely flip burgers.
Some can even do it twice!
“set all environment variables”
More recently its go to discord for the env…no joke.
My face actually dropped when I read this. I will be so mad if I ever encounter this live.
It sucks…and seems to be catching on. Ive seen a quite a few on GitHub that are now referencing using it instead of the issue tracker.
That is so depressing. Literally a markdown file in the repo would be a better issue tracker.
Don’t forget to run your shell over Discord!
This is cursed, but also cool. Hijack another platform for your authentication
Exclusively using Discord as a support channel should get you banned from the internet
The mistake is the assumption of a certain level of end user knowledge.
You have to assume some level of end user knowledge, otherwise every piece of documentation would start with “What a computer does” and “How to turn your computer on.”
I’ve found the best practice is to list your assumptions at the top of the article with links to more detailed instructions.
I do agree, manies have I found documentation saying “make a fresh install of Raspbian” as if I’m using the computer for this single issue
(Disclaimer: I am not running matrix on a Raspberry Pi)
Another case is listing a huge number of steps to do some task, without acting describing what the end goal for each set of instructions is (common in “how to” guides, and especially ones that involve a GUI).
This means that less technical users don’t really understand what is going on and are just following steps in a rote way, and it wastes the time of technical users since they probably know how to achieve each goal already.
It’s easy to forget what other people don’t innately know (or can intuit).
Why’s that a mistake? Not everything is built for a novice
I agree with this. When I publish my code, it is documented for someone in my field with around my level of knowledge. I assume you know DNS, I assume you know what a vector is, I assume you know what a dht is, I assume you know what O(log n) is.
I’m not writing a CS50 course, I’m helping you use the code I wrote.
Might be different for software like libre office which is supposed to be used by anyone, but most software on earth is built with other developers in mind.
This is why I did a “walkthrough test” when I had to write documentation on this sort of thing. I’m a terrible technical writer, so this shit is necessary for me.
I grabbed my friend who knows enough about computers to attempt this, but not enough about infrastructure to automatically know what I meant when I was too vague.
Took two revisions, but the final document was way easier to follow at the end
Reminds me of the time I asked a question about a Magic: The Gathering card tomy local game store’s Facebook page. The card was Sublime Archangel. I asked what happened if it gave a creature Exalted that already had one. Someone sarcastically replied that it already says it on the card. I was a new player, how was I supposed to parse the phrase “If a creature has multiple instances of exalted, each triggers separately”? For all I knew that could mean that they didn’t stack because they would need to trigger together. I didn’t have the vocabulary to understand those things.
I try to remember this when explaining what I might believe are simple concepts to people because that person really upset me.
That’s why blog posts rock. Most popular projects will have a dozen blog posts for different configurations. For example, when looking to set up NextCloud, I found docs for almost all combinations of the following:
- Apache and Nginx configuration
- running through Docker or directly on the host
- MariaDB and Postgres configs (and SQLite, with proper disclaimers)
- Collabora and OnlyOffice config
It does take some knowledge of each of the above if you need one of the few configs that’s not available on a blog post, and some of the posts are outdated, but with a bit of searching almost everything is documented by someone on the internet.
This shouldn’t be necessary (official docs should be more comprehensive), but at least it’s available.
I’d rather have a great documentation than five different blog posts, where some of them might be outdated, wrong or insecure (and you only find out later).
But yes, they are helpful and easily available for popular software.
Okay, please point me to the blog posts that helped you with collabora/onlyoffice. Thanks have NEVER been able to get that to work with my nextcloud (currently using the Docker AIO).
Same with me. I played around with the setup a few times on my local machines. It took quite a bit to get it set up, then I saw an error after a couple of days and gave up. Its easier to just pull down the file and run it locally than use collabora.
I’m not at the same computer I used to look it up, so I don’t have my search history, but I think this one was pretty decent. I don’t use Traefik, but the rest describes the important bits w/ docker compose. I don’t know much about the AIO image though (I used separate images).
That’s just sloppiness.
The information that familiarity gives you is “WTF does this field means”, and it’s the only thing that’s actually there. How you get a value and how a value is formatted are things no amount of expertise will save you from having to tell the computer, and thus you can’t just forget about.
(And let me guess, the software recommended install is a docker image?)
I don’t think it’s (just) that. It’s also a different skill set to write documentation than code, and generally in these kind of open source projects, the people who write the code end up writing the documentation. Even in some commercial projects, the engineers end up writing the docs, because the higher ups don’t see that they’re different skill sets.
100% Agree, it feels like most documentation is written in a way that expects you to already know what it’s talking about… When it’s the documentation’s job to teach me about it.
Honestly, as a newbie to Linux I think the ratio of well documented processes vs. “draw the rest of the fucking owl” is too damn high.
The rule seems to be that CLI familiarity is treated as though its self-evident. The exception is a ground-up documented process with no assumptions of end user knowledge.
If that could be resolved I think it would make the Linux desktop much more appealing to wider demographics.
That said, I’m proud to say that I’ve migrated my entire home studio over to linux and have not nuked my system yet. Yet… Fortunately I have backups set up.
Linux on the desktop almost never needs CLI interaction though. Maybe you’ll need to copy/paste a command from the internet to fix some sketchy hardware, but almost everything works OOTB these days.
However, self-hosting isn’t a desktop Linux thing, it’s a server Linux thing. You can host it on your desktop, but as soon as you do anything remotely server-related, CLI familiarity is pretty much essential.
That depends on your use case for desktop linux of course. For me, yabridge is the tool I needed to run VSTs on Linux. Its CLI only as far as I know.
Don’t get me wrong; I’m not afraid of the CLI. Its just some tools are assuming the end user is a server admin or someone with deeper than the upper crust knowledge of how Linux works.
yabridge
Ah, that’s a pretty niche use-case. But yeah, the deeper you go, the more you’ll have to rely on the CLI.
I always update via CLI 'cause most GUI tools are slow and buggy, so…
I do too, but the GUI tools do work.
Don’t forget the situations where you find a good blog post or article that you can actually follow along until halfway through you get an error that the documentation doesn’t address. So you do some research and find out that they updated the commands for one of the dependency apps, so you try to piece together the updated documents with the original post, until something else breaks and you just end up giving up out of frustration.
That sounds an awful lot like modifying an ESP32 script I’ve been trying to follow from a YouTube tutorial published a while back. Research hasn’t uncovered anything for me to troubleshoot the issue so it’s a really shit experience.
Pre-systemd tutorials 💀
That shouldn’t be too bad if you understand systemd though, right? Or is there something weird i’m missing? Do you have an example guide that illustrates the problem?
CLI familiarity is fine. CD, Nano, mkdir, rm. I am proficient with that. But I am not necessarily proficient with Docker (went with it because it worked nicely for another thing which was well documented and very straight forward). It’s just I’m trying to self host stuff. Some things like Wordpress and Immich are straightforward. Some things aren’t like Matrix and Mastodon. Lemmy is also notoriously bad.
I think if you’re talking wider demographics your model OSs are (obviously) Windows and macOS. People buy into that because CLI familiarity isn’t required. Especially with Apple products everything revolves around simplicity.
I do dream of a day when Linux can (at least somewhat) rival that. I love Linux because I am (or consider myself) intricately familiar with it and I can (theoretically) change every aspect about it. But mutability and limitless possibilities are not what makes an OS lovable to the average user. I think the advent of immutable Linux distros is a step in the right direction for mass adoption. Stuff just needs to work. Googling for StackOverflow or AskUbuntu postings shouldn’t ever be necessary when people just want to do whatever they were doing on Windows with limited technical knowledge.
However on another note, if you’re talking a home studio migration, not sure what that entails, but it sounds rather technical. I don’t want to be the guy to tell you that CLI familiarity is simply par for the course. Maybe your work shouldn’t require terminal interaction. Maybe there is a certain gap between absolutely basic linux tutorials and the more advanced ones like you suggest. Yet what I do want to say is that if you want to do repairwork on your own car it’s not exactly like that is supposed to be an accessible skill to acquire. Even if there are videos explaining step by step what you need to do, eventually you still need to get your own practice in. Stuff will break. We make mistakes and we learn from them. That is the point I’m trying to get at. Not all knowledge can be bestowed from without. Some of it just needs to grow organically from within.
We hold these truths to be self evident
If only i knew the truths 😞
I write technical documentation and training materials as part of my job, and the state of most open source documentation makes me want to stab people with an ice pick.
You’re doing God’s work!
Over my career, it’s sad to see how the technical communications groups are the first to get cut because “developers should document their own code”. No, most can’t. Also, the lack of good documentation leads to churn in other areas. It’s difficult to measure it, but for those in the know, it’s painfully obvious.
Jesus, technical people are some of the worst communicators I’ve ever worked with.
It’s not necessarily their fault though. Y’know who goes into technical jobs? People who often prefer to work with machines, physical stuff, laws of nature, that’s who. And often because it’s MUCH easier than working with people, at least for them.
On top of that, soft skills are HARD. Communication is HARD. It comes easier for some, but it’s a skill like any other. It’s the technical socialites, the diplomatic devs who become the best managers and leaders, due to the rarity of their hybrid skillsets.
I’m in the middle. Just technical enough to mostly understand the devs and understand the implications of plans, and just enough soft skills to turn that into decent documentation, emails, and working with clients.
SUCKS that I’ve gotten a taste of project management and hated the absolute fuck out of it. I probably would’ve been decent at it otherwise.
“Well–well look. I already told you: I deal with the god damn customers so the engineers don’t have to. I have people skills; I am good at dealing with people. Can’t you understand that? What the hell is wrong with you people?”
SUCKS that I’ve gotten a taste of project management and hated the absolute fuck out of it. I probably would’ve been decent at it otherwise.
Good PMs are rare, and precious. You could maybe give it another …
emails
oh, nevermind. :-P
Do you have some reading recommendations on how to write good documentation, e.g. readmes for end users?
Yes. Here: "1.You aren’t writing an SOP for smart or even capable people., every. Single. Person. Needs their hand held all the way through every step regardless of technical skill. "
“2.if you didnt state it needed to be done in the SOP, it will not be done when the end user follows the SOP”
“3.MAKE someone else run through your SOP without you being involved. If they can successfully achieve what they needed using your SOP > congrats. If not > fix the errors that brought you to this mess.”
“4. Everyone is fucking stupid, be clear, and verbose.” We’re talking about where the start menu is, clicking on the “OK” for prompts, how to spell and type things out.
Change my given values per SOP and what it’s for. But those are my main tenants.
In elemental school we had to write instructions on how to make a pb&j sandwich. The teacher then acted out your instructions literally, without adding or removing a step. I don’t think there was a single sandwich made that day.
They should make any developers who are required to write documentation go through this step. It’ll be an interesting day and you’ll actually learn something… I hope.
The PB&J sandwich is a valuable lesson. It needs to be taught to young and old alike.
Beautiful lmao
Excellent notes. If I could add anything it would be on number 4 – just. add. imagery. For the love of your chosen deity, learn the shortcut for a screenshot on your OS. Use it like it’s astro glide and you’re trying to get a Cadillac into a dog house.
The little red circles or arrows you add in your chosen editing software will do more to convey a point than writing a paragraph on how to get to the right menu.
I would also add that you need to explain out-of-home steps, too.
I’m not an idiot but I didn’t go to school for compsci or similar and I don’t do it as a job. So frequently the instructions will go
- Get your IP address by entering this command
- Type your IP address in this line
- Now forward any chosen port to your proxy of choice and don’t forget to check your firewall settings!
My sibling in Eris, most people dont know any of those words.
Absolutely! But I use markdown / Obsidian for my SOPs so images are kinda obnoxious to format. But yes!
I agree, but I don’t think images should be relied on as the primary communicator. I have seen far too many forums/websites/docs with broken images because the host went down. That and archivers are more likely to fail at saving images. Explain it using text and give a reference image to further display the point.
I’ll see about digging up recommendations if I can, but I’m on my phone right now.
My biggest single piece of advice would be this: Understand that your reader does not share your context.
What this means is that you have to question your assumptions. Ask yourself, is this something everyone knows, or something only I know? Is this something that’s an accepted standard, or is it simply my personal default? If it is an accepted standard, how widely can I assume that accepted standard is known?
A really common example of this in self-hosting is poorly documented Docker instructions. A lot of projects suffer from either a lack of instructions for Docker deployment, because they assume that anyone deploying the project has spent 200 hours learning the specifics of chroot and namespaces and can build their own OCI runtime from scratch, or needlessly precise Docker instructions built around one hyper-specific deployment method that completely break when you try to use them in a slightly different context.
A particularly important element of this is explaining the choices you’re making as you make them. For example a lot of self-hosted projects will include a compose file, but will refuse to in any way discuss what elements are required, and what elements are customisable. Someone who knows enough about Docker, and has lots of other detailed knowledge about the Linux file system, networking, etc, can generally puzzle it out for themselves, but most people aren’t going to be coming in with that kind of knowledge. The problem is that programmers do have that knowledge, and as the Xkcd comic says, even when they try to compensate for it they still vastly overestimate how much everyone else knows.
OK, I said I’d try for examples later, but while writing this one did come to mind. Haugene’s transmission-openvpn container implementation has absolutely incredible documentation. Like, this is top tier, absolutely how to do it; https://haugene.github.io/docker-transmission-openvpn/
Starts off with a section that every doc should include; what this does and how it does it. Then goes into specific steps, with, wonder of wonders, notes on what assumptions they’ve made and what things you might want to change. And then, most importantly, detailed instructions on every single configuration option, what it does, and how to set it correctly, including a written example for every single option. Absolutely beautiful. Making docs like this is more work, for sure, but it makes your project - even something like this that’s just implementing other people’s apps in a container - a thousand times more usable.
(I’ve focused on docker in all my examples here, but all of this applies to non-containerized apps too)
That really is a good piece of documentation.
Well a good indicator is if I have to check the source code of a packaged program to understand what something does, the documentation is not good enough. And yes I’ve had to do this far too much.
have to check the source code
Use the source, Luke.
But yeah: disappointing. I just swapped out my Chef ZFS module because, looking at the source, it was incomplete in ways I didn’t want to rat-hole and extend while this other two-piece kit was there.
I should use the source earlier.
Yes @Voroxpete@sh.itjust.works, please do share recommendations
as a chronic documentation reader, the best advice i can give is to document everything Anything that the user can and will potentially interact with, should be extensively documented, including syntax and behavior. Write it like you’re coming back to the project in 5 years after having done nothing and you want to be able to skip right to using it. When we build something ourselves, we often hold a bit of internal knowledge from the design process that never quite goes away, so it’s almost always a lot easier for us to reverse engineer something we’ve made, than it is for someone else with zero fore-knowledge to do it themselves.
Generally this can be a bit of a nightmare, but if you minimize the user facing segment it’s not all that bad, because it’s usually pretty minimal, and what would otherwise be a handful of pages, turns into 10 or maybe 15.
as for existing documentation, the i3wm user guide is really good, it’s pretty minimalist but it leaves you enough to be able to manage.
as a chronic documentation reader, the best advice i can give is to document everything Anything that the user can and will potentially interact with, should be extensively documented, including syntax and behavior.
I don’t know about that. I’ve read some terrible documentation that had everything under the sun. Right now in the library I’m using, the documentation has every available class, every single method, what it’s purpose.
But how to actually use the damn thing? I have to look up blog posts and videos. I actually found someone’s website that had notes about various features that are better than the docs.
There’s a delicate balance of signal vs noise.
yeah, it also helps knowing how to use the thing, but i consider that to be “basic documentation” personally.
Knowing how to set something up is nice, but knowing how to use it properly after setting it up is even nicer.
I used to mock people who make YouTube videos that literally just walk through the documentation. Like bro, get some reading comprehension!
But then when I fumbled with some self hosting tutorials, those YouTube videos were the only thing that made sense, because they’re explaining why and how.
Sorry y’all.
Do you have any tips for writing professional documentation? I want to do some for my workplace but it’s hard to know where to start, how to arrange it, etc
I worked alongside some technical writers in the early post-y2k years at SCO. This was before they sued IBM for code misuse and died by a million legal and PR cuts, thanks to the ‘independent news’ site launched by a ‘recent ex-employee’ to reframe things then and rewrite history after.
We had about 15 tech writers in the company, which when I first arrived seemed like a LOT. I’d never met one, and I’d taken a single tech writing course in college as a filler and found it unchallenging work; so I didn’t value them at the time aside from filling a necessary role that your average nerd could surely fill. Then I saw their work; and it was amazing. It’s one of the product’s strong points, and 20 years later it’s still so head-and-shoulders above the similar offerings by others and since, that it’s a joy to read when I come across it.
Quite simply put, technical writers explain something in a logical, sensible way, where jargon doesn’t blind-side the reader and layout and language are consistent and easy. Hell, spelling is correct; which is a big win over 90% of the current stuff. Tech writers are writers as Lance L said, and thus know about adjective order, prepositional placement, the difference between ‘backup’ and ‘back up’ and all its similar terms; and of course know why e-mail and traffic do not get an S as nouns - ever - even if the popular kids make everyone say it without thinking.
It’s all simple-sounding stuff, and I was fooled into believing it was mundane; but when put together and written with an eye toward a common style it takes a stressful reader looking for a process or a parameter and induces calm for that brief moment required to get into the doc and find the sought-after bit.
Honestly, like the mentors we lost as a working society in the post-y2k bust when the c-suite cleared the ranks of things they didn’t understand, the loss of good technical documentation has a generational effect and will take a massive, sustained effort to reverse.
The worst is when it’s buried in Github issues or in a header file with thousands and thousands of lines of code. Yes I’m looking at you DearImGui, your documentation is awful and I’m already being generous.
I just recently started working with ImGui. Rewrite compiled game engines to add support for HDR into games that never supported it? Sure, easy. I can mod most games in an hour if not minutes.
Make the UI respond like any modern flexible-width UI in the past 15 years? It’s still taking me days. All of the ImGui documentation is hidden behind closed GitHub issues. Like, the expected user experience is to bash your head against something for hours, then submit your very specific issue and wait for the author to tell you what to do if you’re lucky, or link to another issue that vaguely resembles your issue.
I know some projects, WhatWG for one, follow the convention of, if something is unclear in the documentation, the issue does not get closed until that documentation gets updated so there’s no longer any ambiguity or lack of clarity.
Step one: use Dendrite instead.
Step two: come back and help me set up my Dendrite instance, it’s definitely not easier.Step one: email must be much easier, I’ll just make an email server instead.
Step two: screw this, I’m writing letters and posting them.
Isn’t running your own SMTP server effectively impossible nowadays?
Running a server is very doable. There are packages to deploy and configure almost everything for you and removing a ton of headache.
Getting your email recognized as not spam by the major providers is pretty much impossible. You need all sorts of stuff to help verify integrity including special DNS records and public identity keys, but even if you do everything right, your mail can very easily get black holed before it even reaches a user’s inbox because of stupid shit like someone abused your rented server’s IP years ago, and you can’t seem to get it off everyone’s lists.
Email as a decentralized tool has effectively been ruined by spam and anti-spam measures. You’re effectively forced to use a provider because it’s near impossible to make your outgoing mail work as an individual. I think some of those anti-spam measures are anticompetitive, but I do think some are just desperate attempts to reduce the massive flow of spam.
It’s not impossible, many people I know and myself successfully self host their email. Yes it’s not trivial, and yes the ip reputation can be annoying to deal with (but it’s possible to cycle to another server to get another ip), but apart from that, if following the best practices (SPF, DKIM, DMARC, proper setup of the mailserver) once it’s set up it can run for years without issue.
To set things straight, I’m not saying that it is easy, but it’s also not impossible, and only giving up will further contribute to centralized email provider monoculture.
Not for everyone, but for those who can, I feel they should.
This reminds me of when I sent someone a program in a zip folder. Windows now opens zip folders by default, and it looks just like any other folder.
So of course they opened the zip and double clicked the exe, but everyone knows you can’t open an exe inside a zip folder (at least, if the exe depends on the folders and files around it). If you try to, windows will extract the exe into a temp space, but leave all the dependencies behind. So the exe promptly crashes.
I didn’t think I needed to specify “you need to extract the contents of the zip folder first, then run the exe.” It feels like saying “you need to take the blender out of the box before you can use it. And not just the _base _ of the blender, you have to take out all the parts.”
Some things just feel so much like second nature that we forget.
In many ways, the silky-smooth convenience offered by modern computer software makes everything much harder to learn about and understand. For anyone that used zip files before this Windows feature, the problem is obvious - but for younger people it’s not obvious at all. Heck, a lot of people can’t even tell whether or not a file is locally on their computer - let alone whether it is compressed in some other file.
Doesn’t Windows give a popup saying “Do you want to extract the folder before running the executable” anymore?
Edit: typo (funning to running)
No, it does.
Perhaps this occurred in the small window of time when it had been implemented and it didn’t ask, or perhaps they just said no.
Regardless, I had to troubleshoot
Not that I know of. If I know it correctly (not doing it very often as I usually extract the whole content anyway) it just asks if I want to run the file.
But I could be very wrong.
I totally and completely blame Microsoft for this. They do so many other ridiculous things in the name of not confusing the average tech illiterate user.
Clicking a Zip file and having it transparently open and treating it like a regular folder when it is not. This. THIS is borderline criminal.
Propose a better way to browse the contents of a zip folder in a native 1st party way
Have a popup text line in explorer that says “you are browsing inside of a compressed file, you must extract the contents to use them” or something. The functionality is already there, when you go to “network” it says “network sharing and discovery is turned off, click here to turn it on”
The operating system could mount it as a virtual drive, then all its contents could be used directly just like any regular folder.
Imo not really noob-user friendly.
My proposal: Keep current behaviour and make a prompt if the user tries to run an executable. Prompt should be something like “You are trying to open an executable, would you like to extract the whole folder in the current directory?”. This way the user can still browse the zip with relative ease.
Upside from Windows: We have only a handful of extensions unlike (afaik) Linux where everything can be made executable and be run.Imo not really noob-user friendly.
In what way? It would make it entirely invisible that the archive file isn’t just a normal folder, it would be possible to use it just as if it were. What would be unfriendly about that?
Something like this would be helpful:
Perfect.
There should be instructions that range from beginner, where every little step is included as well as major details as to why - all the way up to expert, which are just a few sentences.
Unless it’s a company, good luc…
Hay, how would you like writing documentation for all these open source projects? We would be ever greatful, you could even put your name in the credits!
One of the few things that Mac kind of got right. Every application is actually a deep tree with all kinds of crap all over the place but they never let the user see that.
Am I the only one in this thread that took this as it’s asking for a clear text credential which is a terrible idea?
A temporary one that you’re expected to remove as soon as you’ve created the admin user(s) you need, but yes. It should only be there during initial setup and ideally removed before the server is ever exposed to the internet.
The “if you no longer need it” part doesn’t really suggest that you are expected to do it as part of normal operation.
Yes because having a user remember to do something is a great line of defense, better than encrypting it from the get go. It should just be encrypted in the file.
I think that’s the way both Splunk and JFrog work – you generate or enter a password into the key field in a YAML file somewhere, start the service, and next time you come back the field’s been encrypted.
The step tells you to remove it after at least
update: It’s all working perfectly!
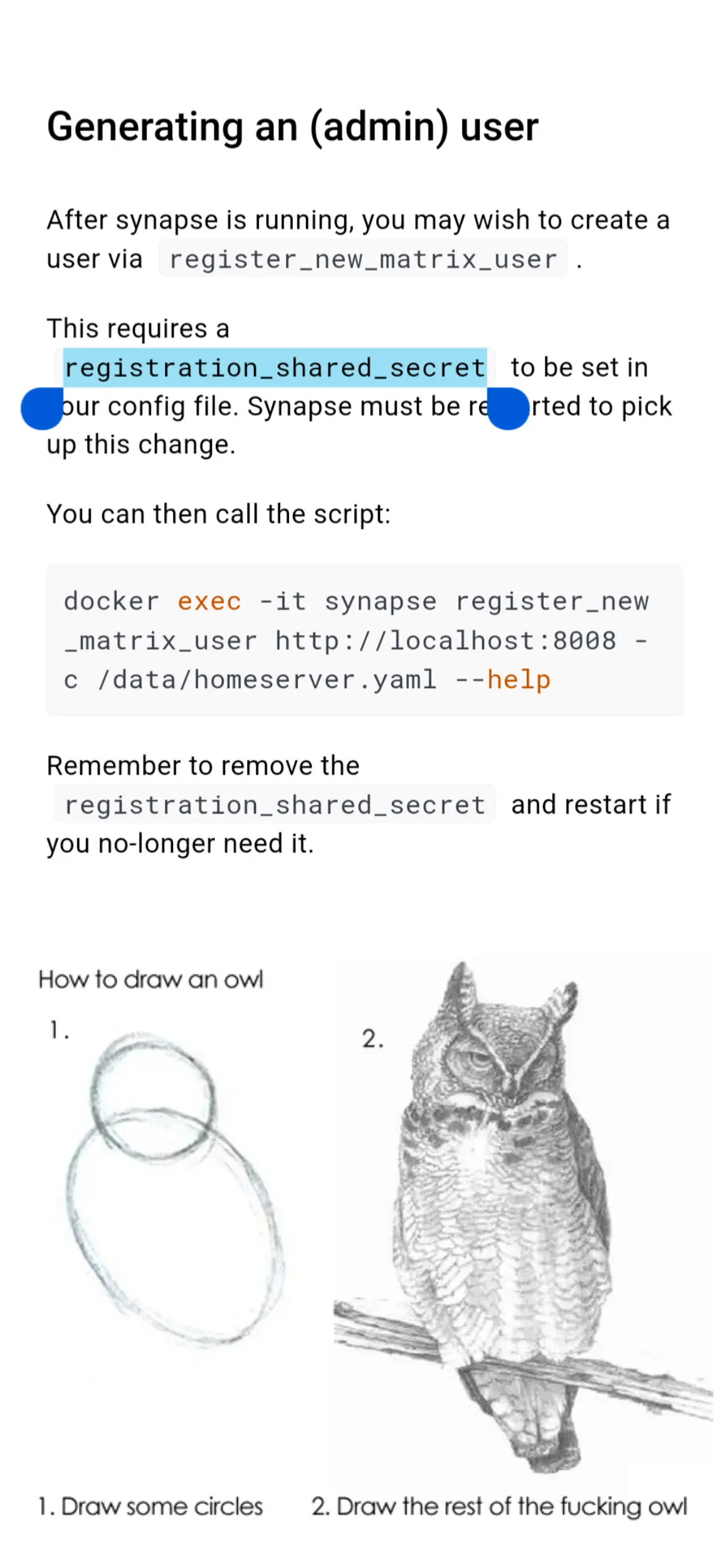
Here’s some more of the owl, the official docs: https://element-hq.github.io/synapse/latest/usage/configuration/config_documentation.html#registration_shared_secret
So add this to your matrix config:
registration_shared_secret: <PRIVATE STRING>
I’m guessing this string can be whatever you want it to be.
But yeah, I agree in general, some of the docs can be pretty opaque. For example, I wanted to configure NextCloud w/ Collabora in Docker, and I kept getting errors when trying to do what a few sites recommended. I ended up figuring it out, but only through trial and error. I’m going to go through the same pain this weekend when I try out ownCloud Infinite Scale up and running to compare.
I had very similar experiences with OCIS. Got it all set up following the quick start guide, found extremely odd and unacceptable behaviour with storage space ballooning, start troubleshooting and find “oh you had to do this, this and this manually, it’s in the docs” It is in the docs, but never referenced by any other part of the docs. Because why would you mention the thing that the admin must manually set up in 100% of installs in your setup guide?
Anyway I’ve become that guy ranting on the internet that I don’t want to be. So just so you don’t suffer as much as I did; you have to create scheduled tasks via cron or your preference of scheduler to clean your uploads folder and data blobs. This also did not fix my specific issue and I ended up giving up on OCIS and sticking to Nextcloud.
Huh, thanks!
I’m going to run both in parallel for a month or so before trying to get my SO to use it so I can better estimate the WAF. So far, NextCloud is good enough, but it’s kinda slow (and I have Redis configured) despite being on pretty beefy hardware (Ryzen 1700 w/ 16GB RAM). I really hate PHP, so I’d prefer a project I can contribute to if needed. I worked w/ Go for almost 10 years, so OCIS would be a natural fit, but I’d still contribute patches for PHP if that really was the best tool for the job. But I’m not going to get involved unless the project already does what I need (my contributions would be for smaller bug fixes).
But yeah, the OCIS docs look kinda mediocre from the little I’ve read of them. But at least I don’t need to mess w/ PHP config most likely and can hopefully just forward HTTP requests to it.
The move from php to go and the slowness of NC is what attracted me to the project. But I’m going to wait a bit longer until we’re flush with 3rd party setup guides cause I simply do not have the time to wade through their docs.
Yup, that’s why I started w/ NextCloud. It was painful enough getting Collabora working with NC, so hopefully OCIS is easier now that I know my Collabora setup at least works.
Yeah that’s the problem is guessing what they meant.
Matrix and its implementations like Synapse have a very intimidating architecture (I’d go as far as to call most of the implementations somewhat overengineered) and the documentation ranges from inconsistent to horrific. I ran into this particular situation myself, Fortunately this particular step you’re overthinking it. You can use any random string you want. It doesn’t even have to be random, just as long as what you put in the config file matches. It’s basically just a temporary admin password.
Matrix was by far the worst thing I’ve ever tried to self-host. It’s a hot mess. Good luck, I think you’re close to the finish line.
funnily there’s an… ansible i think? project that makes selfhosting synapse easy as fuck, you basically just go “ansible deploy synapse” or whatever the syntax is and it does almost everything for you.
My favorite thing is purging remote cached media.
You need a timestamp, which is fine.
You just need to figure out how many miliseconds since the unix epoch the media you want to purge was uploaded, and then offset the time to only purge that old or older.
Easy!
So, you need a unix time value followed by 000?
That first part you can calculate with
date +%s -d '2024-07-02 12:00'.I ended up doing basically that.
Current time in ms, minus 2629800000 (a month) = timestamp to use to prune from.
Matrix seemed interesting right until I got to self hosting it. Then, getting to know it from up close, and the absolute trainwreck that the protocol is, made me love XMPP. Matrix has no excuse for being so messy and fragile at this point. You do you, but I decided that it isn’t worth my sysadmin time (especially when something like ejabberd is practically fire and forget).
I still have to sort out having a different server name to the access name so I can use the domain as well. Do I just put a field into the config like the rest? Can it go anywhere?
Ok now it’s asking me to serve a “.well_known” file like… How?
Ah, that goes on my main server. I’m learning.
It’s also optional, my first setup I just pointed to the matrix subdomain
this meme got so much funnier after I realized it was synapse/matrix
Protip: Use Conduit instead of Synapse. It’s significantly lighter than Synapse, easier to run, and I guess you can be a cool kid by running something written in Rust. The documentation is even worse though :/ https://conduit.rs/
deleted by creator
Dendrite is still in beta and isn’t feature-complete. I tried all three (Synapse, Dendrite and Conduit) and Conduit worked the best for me - I found it to be the most reliable and use the least amount of RAM. It also uses an embedded database (RocksDB) which makes setup a bit easier.
I tried joining several large Matrix rooms from my server, and the experience with Synapse was dreadful. It was using 100% of one core for long periods of time. In some cases it would just fall over and not join the room. Dendrite and Conduit are better in that regard.
Conduit’s weak point is its documentation. I had to read Synapse’s documentation to understand a few key concepts. I’ve been meaning to help write docs for Conduit but just haven’t had time. I’ve got a PR to improve the styling of the docs at least, but need to do some tweaks to it.
Dearest ChatGPT, What the fuck is a shared secret?
As an LLM, I don’t truly understand the notion of sharing, but I can point you to a few resources that may help you understand more. It’s important to remember that human interaction is complex and varied, and different people will have different opinions.
Here are some ideas to get you started.
- “Sharing is Caring”. “Sharing is Caring” is a popular phrase to explain the meaning of sharing. If you really care about your secret, that way you are sharing it with the loved ones in your life.
- Valuable things, such as companies, are often divided into shares. If you divide your secret and sell parts of it to different people on the internet, it becomes a shared secret.
- “A problem shared is a problem halved.” This is another popular phrase, showing that if you halve your secret, i.e. make it smaller, or less secret, then you are sharing it.
Overall, humans value both secrets and sharing as a way to build and strengthen community. A shared secret is the ultimate expression of humanity in community.
I hope that answers your question. If there’s anything else I can help you with, please let me know.
AI couldn’t even bullshit as good as this and that’s all it’s for.
It’s the thing you only tell your “ride-or-die bitch” server.
An application password, basically
Being able to find and read software documentation and knowing how to use the tools that automate software deployment are why SRE/devops/cloud guys get paid the big bucks.
I definitely recommend synapse over dendrite or conduit btw. dendrite and conduit have a bunch of missing features, and my first attempt at dendrite server shat the bed with its NATS store and died. I definitely recommend Synapse for all matrix servers going forward.
The .well-known entries I found were the hardest to test, since synapse doesn’t provide a web server for them, and Element throws a fit if you don’t have CORS set up exactly in the way it wants you to.
I mostly have my matrix server working now, with bridges even. However, Element randomly logs itself out on a daily basis which is really frustrating :/
I mainly want matrix for the bridges.
I haven’t done any programming in over 20 years, but I think I can make a contribution to projects by trying to improve documentation, once I start using some projects
I mean… Bad documentation isn’t specific to selfhosting.
They’re not long about matrix docs though. I tried to set it up a few years ago and it was irritating enough that I never got through it.
Most Dockers aren’t that bad though.






















{kind=link}